{kind=link}
You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.

Dask Arrays - parallelized numpy#
Parallel, larger-than-memory, n-dimensional array using blocked algorithms.
Parallel: Uses all of the cores on your computer
Larger-than-memory: Lets you work on datasets that are larger than your available memory by breaking up your array into many small pieces, operating on those pieces in an order that minimizes the memory footprint of your computation, and effectively streaming data from disk.
Blocked Algorithms: Perform large computations by performing many smaller computations.

In other words, Dask Array implements a subset of the NumPy ndarray interface using blocked algorithms, cutting up the large array into many small arrays. This lets us compute on arrays larger than memory using all of our cores. We coordinate these blocked algorithms using Dask graphs.
In this notebook, we’ll build some understanding by implementing some blocked algorithms from scratch. We’ll then use Dask Array to analyze large datasets, in parallel, using a familiar NumPy-like API.
Related Documentation
Create datasets#
Create the datasets you will be using in this notebook:
[1]:
%run prep.py -d random
- Generating random array data...
Start the Client#
[2]:
from dask.distributed import Client
client = Client(n_workers=4)
client
[2]:
Client
Client-0a1c484d-b995-11f0-9116-7c1e521a36f9
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: http://127.0.0.1:8787/status |
Cluster Info
LocalCluster
9c38703e
| Dashboard: http://127.0.0.1:8787/status | Workers: 4 |
| Total threads: 4 | Total memory: 15.62 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-cdd61857-f6d7-456a-9122-11edfc002c24
| Comm: tcp://127.0.0.1:41849 | Workers: 4 |
| Dashboard: http://127.0.0.1:8787/status | Total threads: 4 |
| Started: Just now | Total memory: 15.62 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:46423 | Total threads: 1 |
| Dashboard: http://127.0.0.1:39171/status | Memory: 3.91 GiB |
| Nanny: tcp://127.0.0.1:46111 | |
| Local directory: /tmp/dask-worker-space/worker-38cnxk4u | |
Worker: 1
| Comm: tcp://127.0.0.1:36699 | Total threads: 1 |
| Dashboard: http://127.0.0.1:44403/status | Memory: 3.91 GiB |
| Nanny: tcp://127.0.0.1:37597 | |
| Local directory: /tmp/dask-worker-space/worker-xdnot0kn | |
Worker: 2
| Comm: tcp://127.0.0.1:44849 | Total threads: 1 |
| Dashboard: http://127.0.0.1:43521/status | Memory: 3.91 GiB |
| Nanny: tcp://127.0.0.1:39399 | |
| Local directory: /tmp/dask-worker-space/worker-lcrjwfg9 | |
Worker: 3
| Comm: tcp://127.0.0.1:37273 | Total threads: 1 |
| Dashboard: http://127.0.0.1:46209/status | Memory: 3.91 GiB |
| Nanny: tcp://127.0.0.1:33293 | |
| Local directory: /tmp/dask-worker-space/worker-w7uvwaxo | |
Blocked Algorithms in a nutshell#
Let’s do side by side the sum of the elements of an array using a NumPy array and a Dask array.
[3]:
import numpy as np
import dask.array as da
[4]:
# NumPy array
a_np = np.ones(10)
a_np
[4]:
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
We know that we can use sum() to compute the sum of the elements of our array, but to show what a blocksized operation would look like, let’s do:
[5]:
a_np_sum = a_np[:5].sum() + a_np[5:].sum()
a_np_sum
[5]:
10.0
Now notice that each sum in the computation above is completely independent so they could be done in parallel. To do this with Dask array, we need to define our “slices”, we do this by defining the amount of elements we want per block using the variable chunks.
[6]:
a_da = da.ones(10, chunks=5)
a_da
[6]:
|
||||||||||||||||
Important!
Note here that to get two blocks, we specify chunks=5, in other words, we have 5 elements per block.
[7]:
a_da_sum = a_da.sum()
a_da_sum
[7]:
|
||||||||||||||||
Task Graphs#
In general, the code that humans write rely on compilers or interpreters so the computers can understand what we wrote. When we move to parallel execution there is a desire to shift responsibility from the compilers to the human, as they often bring the analysis, optimization, and execution of code into the code itself. In these cases, we often represent the structure of our program explicitly as data within the program itself.
In Dask we use task scheduling, where we break our program into into many medium-sized tasks or units of computation.We represent these tasks as nodes in a graph with edges between nodes if one task depends on data produced by another. We call upon a task scheduler to execute this graph in a way that respects these data dependencies and leverages parallelism where possible, so multiple independent tasks can be run simultaneously.
[8]:
# visualize the low level Dask graph using cytoscape
a_da_sum.visualize(engine="cytoscape")
[8]:
[9]:
a_da_sum.compute()
[9]:
10.0
Performance comparison#
Let’s try a more interesting example. We will create a 20_000 x 20_000 array with normally distributed values, and take the mean along one of its axis.
Note:
If you are running on Binder, the Numpy example might need to be a smaller one due to memory issues.
Numpy version#
[10]:
%%time
xn = np.random.normal(10, 0.1, size=(30_000, 30_000))
yn = xn.mean(axis=0)
yn
CPU times: user 20.5 s, sys: 697 ms, total: 21.2 s
Wall time: 20.4 s
[10]:
array([ 9.99890846, 9.99954189, 10.0004539 , ..., 9.99912923,
9.99925533, 9.99984859])
Dask array version#
[11]:
xd = da.random.normal(10, 0.1, size=(30_000, 30_000), chunks=(3000, 3000))
xd
[11]:
|
||||||||||||||||
[12]:
xd.nbytes / 1e9 # Gigabytes of the input processed lazily
[12]:
7.2
[13]:
yd = xd.mean(axis=0)
yd
[13]:
|
||||||||||||||||
[14]:
%%time
xd = da.random.normal(10, 0.1, size=(30_000, 30_000), chunks=(3000, 3000))
yd = xd.mean(axis=0)
yd.compute()
CPU times: user 565 ms, sys: 95.9 ms, total: 661 ms
Wall time: 8.87 s
[14]:
array([10.00006416, 9.99967447, 10.00078189, ..., 10.00044632,
10.00071815, 10.00000633])
Questions to think about:
What happens if the Dask chunks=(10000,10000)?
What happens if the Dask chunks=(30,30)?
Exercise:
For Dask arrays, compute the mean along axis=1 of the sum of the x array and its transpose.
[15]:
# Your code here
Solution
[16]:
x_sum = xd + xd.T
res = x_sum.mean(axis=1)
res.compute()
[16]:
array([20.00000859, 19.99980514, 20.00098232, ..., 20.00065408,
20.00069767, 19.99991412])
Choosing good chunk sizes#
This section was inspired on a Dask blog by Genevieve Buckley you can read it here
A common problem when getting started with Dask array is determine what is a good chunk size. But what is a good size, and how do we determine this?
Get to know the chunks#
We can think of Dask arrays as a big structure composed by chunks of a smaller size, where these chunks are typically an a single numpy array, and they are all arranged to form a larger Dask array.
If you have a Dask array and want to know more information about chunks and their size, you can use the chunksize and chunks attributes to access this information. If you are in a jupyter notebook you can also visualize the Dask array via its HTML representation.
[17]:
darr = da.random.random((1000, 1000, 1000))
darr
[17]:
|
||||||||||||||||
Notice that when we created the Dask array, we did not specify the chunks. Dask has set by default chunks='auto' which accommodates ideal chunk sizes. To learn more on how auto-chunking works you can go to this documentation https://docs.dask.org/en/stable/array-chunks.html#automatic-chunking
darr.chunksize shows the largest chunk size. If you expect your array to have uniform chunk sizes this is a a good summary of the chunk size information. But if your array have irregular chunks, darr.chunks will show you the explicit sizes of all the chunks along all the dimensions of your dask array.
[18]:
darr.chunksize
[18]:
(255, 255, 255)
[19]:
darr.chunks
[19]:
((255, 255, 255, 235), (255, 255, 255, 235), (255, 255, 255, 235))
Let’s modify our example to see explore chunking a bit more. We can rechunk our array:
[20]:
darr = darr.rechunk({0: -1, 1: 100, 2: "auto"})
[21]:
darr
[21]:
|
||||||||||||||||
[22]:
darr.chunksize
[22]:
(1000, 100, 167)
[23]:
darr.chunks
[23]:
((1000,),
(100, 100, 100, 100, 100, 100, 100, 100, 100, 100),
(167, 167, 167, 167, 167, 165))
Exercise:
What does -1 do when specify as the chunk on a certain axis?
Too small is a problem#
If your chunks are too small, the amount of actual work done by every task is very tiny, and the overhead of coordinating all these tasks results in a very inefficient process.
In general, the dask scheduler takes approximately one millisecond to coordinate a single task. That means we want the computation time to be comparatively large, i.e in the order of seconds.
Intuitive analogy by Genevieve Buckley:
Lets imagine we are building a house. It is a pretty big job, and if there were only one worker it would take much too long to build. So we have a team of workers and a site foreman. The site foreman is equivalent to the Dask scheduler: their job is to tell the workers what tasks they need to do.Say we have a big pile of bricks to build a wall, sitting in the corner of the building site. If the foreman (the Dask scheduler) tells workers to go and fetch a single brick at a time, then bring each one to where the wall is being built, you can see how this is going to be very slow and inefficient! The workers are spending most of their time moving between the wall and the pile of bricks. Much less time is going towards doing the actual work of mortaring bricks onto the wall.Instead, we can do this in a smarter way. The foreman (Dask scheduler) can tell the workers to go and bring one full wheelbarrow load of bricks back each time. Now workers are spending much less time moving between the wall and the pile of bricks, and the wall will be finished much quicker.
Too big is a problem#
If your chunks are too big, this is also a problem because you will likely run out of memory. You will start seeing in the dashboard that data is being spill to disk and this will lead to performance decrements.
If we load to much data into memory, Dask workers will start to spill data to disk to avoid crashing. Spilling data to disk will slow things down significantly, because of all the extra read and write operations to disk. This is definitely a situation that we want to avoid, to watch out for this you can look at the worker memory plot on the dashboard. Orange bars are a warning you are close to the limit, and gray means data is being spilled to disk.
To watch out for this, look at the worker memory plot on the Dask dashboard. Orange bars are a warning you are close to the limit, and gray means data is being spilled to disk - not good! For more tips, see the section on using the Dask dashboard below. To learn more about the memory plot, check the dashboard documentation.
Rules of thumb#
Users have reported that chunk sizes smaller than 1MB tend to be bad. In general, a chunk size between 100MB and 1GB is good, while going over 1 or 2GB means you have a really big dataset and/or a lot of memory available per worker.
Upper bound: Avoid very large task graphs. More than 10,000 or 100,000 chunks may start to perform poorly.
Lower bound: To get the advantage of parallelization, you need the number of chunks to at least equal the number of worker cores available (or better, the number of worker cores times 2). Otherwise, some workers will stay idle.
The time taken to compute each task should be much larger than the time needed to schedule the task. The Dask scheduler takes roughly 1 millisecond to coordinate a single task, so a good task computation time would be in the order of seconds (not milliseconds).
Chunks should be aligned with array storage on disk. Modern NDArray storage formats (HDF5, NetCDF, TIFF, Zarr) allow arrays to be stored in chunks so that the blocks of data can be pulled efficiently. However, data stores often chunk more finely than is ideal for Dask array, so it is common to choose a chunking that is a multiple of your storage chunk size, otherwise you might incur high overhead. For example, if you are loading data that is chunked in blocks of (100, 100), the you might might choose a chunking strategy more like (1000, 2000) that is larger but still divisible by (100, 100).
For more more advice on chunking see https://docs.dask.org/en/stable/array-chunks.html
Example of chunked data with Zarr#
Zarr is a format for the storage of chunked, compressed, N-dimensional arrays. Zarr provides classes and functions for working with N-dimensional arrays that behave like NumPy arrays (Dask array behave like Numpy arrays) but whose data is divided into chunks and each chunk is compressed. If you are already familiar with HDF5 then Zarr arrays provide similar functionality, but with some additional flexibility.
For extra material check the Zarr tutorial
Let’s read an array from zarr:
[24]:
import zarr
[25]:
a = da.from_zarr("data/random.zarr")
[26]:
a
[26]:
|
||||||||||||||||
Notice that the array is already chunked, and we didn’t specify anything when loading it. Now notice that the chunks have a nice chunk size, let’s compute the mean and see how long it takes to run
[27]:
%%time
a.mean().compute()
CPU times: user 65.8 ms, sys: 11.2 ms, total: 77.1 ms
Wall time: 229 ms
[27]:
0.49997303111539
Let’s load a separate example where the chunksize is much smaller, and see what happen
[28]:
b = da.from_zarr("data/random_sc.zarr")
b
[28]:
|
||||||||||||||||
[29]:
%%time
b.mean().compute()
CPU times: user 19.6 s, sys: 1.54 s, total: 21.2 s
Wall time: 31 s
[29]:
0.5000435557912054
Exercise:#
Provide a chunksize when reading b that will improve the time of computation of the mean. Try multiple chunks values and see what happens.
[30]:
# Your code here
[31]:
# 1 possible Solution (imitate original). chunks will vary if you are in binder
c = da.from_zarr("data/random_sc.zarr", chunks=(6250000,))
c
[31]:
|
||||||||||||||||
[32]:
%%time
c.mean().compute()
CPU times: user 43.3 ms, sys: 8.53 ms, total: 51.8 ms
Wall time: 740 ms
[32]:
0.5000435557912054
Xarray#
In some applications we have multidimensional data, and sometimes working with all this dimensions can be confusing. Xarray is an open source project and Python package that makes working with labeled multi-dimensional arrays easier.
Xarray is inspired by and borrows heavily from pandas, the popular data analysis package focused on labeled tabular data. It is particularly tailored to working with netCDF files, which were the source of xarray’s data model, and integrates tightly with Dask for parallel computing.
Xarray introduces labels in the form of dimensions, coordinates and attributes on top of raw NumPy-like arrays, which allows for a more intuitive, more concise, and less error-prone developer experience.
Let’s learn how to use xarray and Dask together:
[33]:
import xarray as xr
[34]:
ds = xr.tutorial.open_dataset(
"air_temperature",
chunks={ # this tells xarray to open the dataset as a dask array
"lat": 25,
"lon": 25,
"time": -1,
},
)
ds
[34]:
<xarray.Dataset> Size: 31MB
Dimensions: (lat: 25, time: 2920, lon: 53)
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float64 31MB dask.array<chunksize=(2920, 25, 25), meta=np.ndarray>
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...[35]:
ds.air
[35]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53)> Size: 31MB
dask.array<open_dataset-air, shape=(2920, 25, 53), dtype=float64, chunksize=(2920, 25, 25), chunktype=numpy.ndarray>
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
Attributes:
long_name: 4xDaily Air temperature at sigma level 995
units: degK
precision: 2
GRIB_id: 11
GRIB_name: TMP
var_desc: Air temperature
dataset: NMC Reanalysis
level_desc: Surface
statistic: Individual Obs
parent_stat: Other
actual_range: [185.16 322.1 ][36]:
ds.air.chunks
[36]:
((2920,), (25,), (25, 25, 3))
[37]:
mean = ds.air.mean("time") # no activity on dashboard
mean # contains a dask array
[37]:
<xarray.DataArray 'air' (lat: 25, lon: 53)> Size: 11kB dask.array<mean_agg-aggregate, shape=(25, 53), dtype=float64, chunksize=(25, 25), chunktype=numpy.ndarray> Coordinates: * lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0 * lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
[38]:
# we will see dashboard activity
mean.load()
[38]:
<xarray.DataArray 'air' (lat: 25, lon: 53)> Size: 11kB
array([[260.37644178, 260.18305137, 259.88662671, ..., 250.81590068,
251.93811644, 253.43804795],
[262.73439384, 262.79397603, 262.74933904, ..., 249.75590411,
251.58575685, 254.35926027],
[264.7687637 , 264.32730822, 264.06169521, ..., 250.60789041,
253.58351027, 257.71559932],
...,
[297.64986301, 296.95333219, 296.62931507, ..., 296.81092466,
296.28796233, 295.81645548],
[298.12920205, 297.93700685, 297.47039384, ..., 296.85954795,
296.7770274 , 296.44383562],
[298.36615068, 298.38573973, 298.11414384, ..., 297.33820548,
297.28144521, 297.30510274]])
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0Standard Xarray Operations#
Let’s grab the air variable and do some operations. Operations using xarray objects are identical, regardless if the underlying data is stored as a Dask array or a NumPy array.
[39]:
dair = ds.air
[40]:
dair2 = dair.groupby("time.month").mean("time")
dair_new = dair - dair2
dair_new
[40]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53, month: 12)> Size: 371MB dask.array<sub, shape=(2920, 25, 53, 12), dtype=float64, chunksize=(2920, 25, 25, 1), chunktype=numpy.ndarray> Coordinates: * lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0 * lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0 * time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00 * month (month) int64 96B 1 2 3 4 5 6 7 8 9 10 11 12
Call .compute() or .load() when you want your result as a xarray.DataArray with data stored as NumPy arrays.
[41]:
# things happen in the dashboard
dair_new.load()
[41]:
<xarray.DataArray 'air' (time: 2920, lat: 25, lon: 53, month: 12)> Size: 371MB
array([[[[-5.14975806e+00, -5.47709821e+00, -9.83161290e+00, ...,
-2.06137097e+01, -1.25446667e+01, -6.77088710e+00],
[-3.88592742e+00, -3.90562500e+00, -8.17975806e+00, ...,
-1.87126210e+01, -1.11448750e+01, -5.52096774e+00],
[-2.71495968e+00, -2.44830357e+00, -6.68943548e+00, ...,
-1.70037097e+01, -9.99704167e+00, -4.41282258e+00],
...,
[-1.02609677e+01, -9.05825893e+00, -9.39375000e+00, ...,
-1.53932661e+01, -1.01605833e+01, -6.97169355e+00],
[-8.58774194e+00, -7.50187500e+00, -7.61467742e+00, ...,
-1.35697581e+01, -8.43441667e+00, -5.52358871e+00],
[-7.04653226e+00, -5.84366071e+00, -5.70947581e+00, ...,
-1.18160887e+01, -6.54195833e+00, -4.02806452e+00]],
[[-5.05750000e+00, -3.99995536e+00, -9.17193548e+00, ...,
-2.52225000e+01, -1.53297500e+01, -5.93338710e+00],
[-4.40729839e+00, -3.25986607e+00, -8.36620968e+00, ...,
-2.44295565e+01, -1.41292083e+01, -5.66028226e+00],
[-4.01028226e+00, -2.77741071e+00, -7.87350806e+00, ...,
-2.40149194e+01, -1.34914583e+01, -5.78564516e+00],
...
[ 3.33870968e-01, 1.17812500e+00, 8.39112903e-01, ...,
-3.56907258e+00, -2.47420833e+00, -1.16564516e+00],
[ 6.08588710e-01, 1.47191964e+00, 1.11951613e+00, ...,
-3.59879032e+00, -2.50400000e+00, -1.15669355e+00],
[ 6.59838710e-01, 1.48723214e+00, 1.03766129e+00, ...,
-3.84629032e+00, -2.71833333e+00, -1.33141129e+00]],
[[ 5.35524194e-01, 4.00892857e-01, 3.08104839e-01, ...,
-1.68060484e+00, -1.12145833e+00, -1.90927419e-01],
[ 8.51572581e-01, 8.73303571e-01, 6.26653226e-01, ...,
-1.33471774e+00, -7.66625000e-01, 1.03225806e-01],
[ 1.04084677e+00, 1.23178571e+00, 8.63104839e-01, ...,
-1.06616935e+00, -5.31083333e-01, 3.14475806e-01],
...,
[ 4.71854839e-01, 1.32928571e+00, 1.15487903e+00, ...,
-3.23411290e+00, -2.23962500e+00, -1.11032258e+00],
[ 4.14193548e-01, 1.23397321e+00, 1.07866935e+00, ...,
-3.47326613e+00, -2.56187500e+00, -1.37540323e+00],
[ 5.32258065e-02, 8.10000000e-01, 6.73266129e-01, ...,
-4.07241935e+00, -3.12895833e+00, -1.84770161e+00]]]])
Coordinates:
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
* month (month) int64 96B 1 2 3 4 5 6 7 8 9 10 11 12Time Series Operations with xarray#
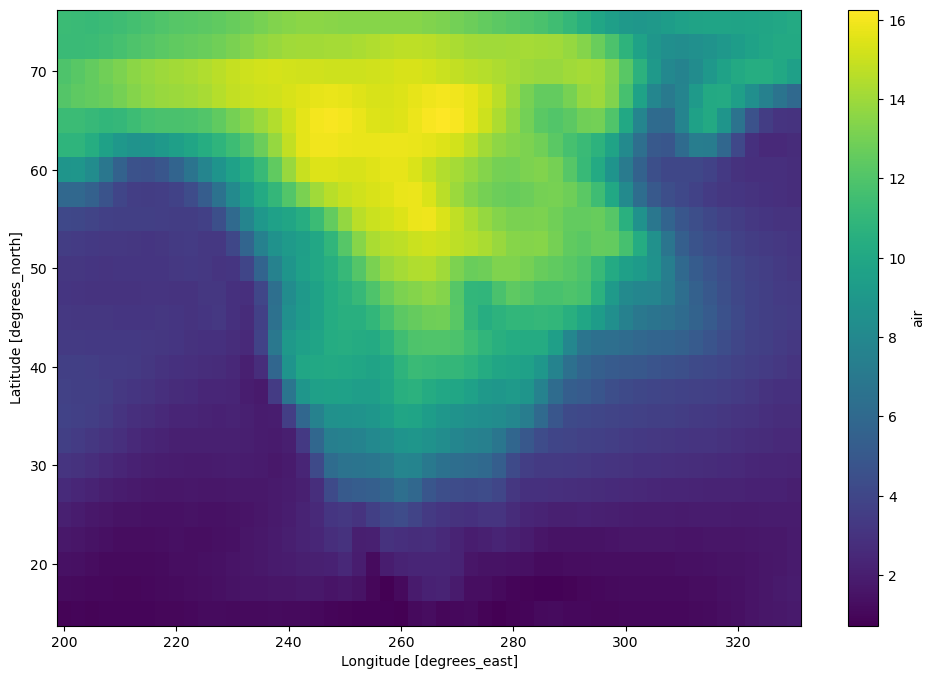
Because we have a datetime index time-series operations work efficiently, for example we can do a resample and then plot the result.
[42]:
dair_resample = dair.resample(time="1w").mean("time").std("time")
[43]:
dair_resample.load().plot(figsize=(12, 8))
[43]:
<matplotlib.collections.QuadMesh at 0x7f5dba6b8610>
Learn More#
Both xarray and zarr have their own tutorials that go into greater depth:
Close your cluster#
It’s good practice to close any Dask cluster you create:
[44]:
client.shutdown()